Optimal binary search trees
Optimal binary search trees
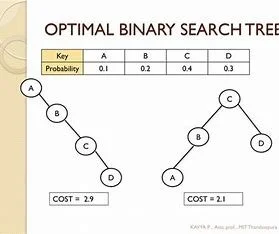
If we don't plan on modifying a search tree, and we know exactly how often each item will be accessed, we can construct an optimal binary search tree, which is a search tree where the average cost of looking up an item (the expected search cost) is minimized.
Even if we only have estimates of the search costs, such a system can considerably speed up lookups on average. For example, if you have a BST of English words used in a spell checker, you might balance the tree based on word frequency in text corpora, placing words like "the" near the root and words like "agerasia" near the leaves.
Such a tree might be compared with Huffman trees, which similarly seek to place frequently-used items near the root in order to produce a dense information encoding; however, Huffman trees only store data elements in leaves and these elements need not be ordered.
If we do not know the sequence in which the elements in the tree will be accessed in advance, we can use splay trees which are asymptotically as good as any static search tree we can construct for any particular sequence of lookup operations.
Alphabetic trees are Huffman trees with the additional constraint on order, or, equivalently, search trees with the modification that all elements are stored in the leaves. Faster algorithms exist for optimal alphabetic binary trees (OABTs).
Huffman’s binary tree structure: allows rapid indexing and searching of words in binary format